dex文件解析
学壳先学结构捏,前面师傅丢了3篇,深度优先看了(
前置
JVM
JVM是Java Virtual Machine的简称,即Java虚拟机
DVM
DVM是Dalvik Virtual Machine的简称,是Android4.4及以前使用的虚拟机,所有Android程序都运行在Android系统进程中,每个进程对应着一个Dalvik虚拟机实例。
JVM和DVM都提供了对对象生命周期管理,堆栈管理,安全和异常管理及垃圾回收等重要功能。
但是DVM却不能和JVM一样能直接运行Java字节码,它只能运行.dex文件,而这个.dex文件则是由Java字节码通过Android的dx工具生成的文件。
ART
ART是Android Runtime,在Android5.0开始使用ART虚拟机来替代Dalvik虚拟机,为什么Google要换Android程序运行的虚拟机呢 因为ART虚拟机更优秀。
前面说了Dalvik虚拟机会在APP打开时去运行.dex文件,而这个是实时的,也就是JIT特性(Just In Time),这也就会导致在启动APP时会先将.dex文件转换成机器码,这就导致了APP启动慢的问题。
而ART虚拟机有个很好的特性叫做AOT(ahead of time),这个特性可以在安装APK的时候将dex直接处理成可直接供ART虚拟机使用的机器码,ART虚拟机将.dex文件转换成可直接运行的.oat文件,而且ART虚拟机天生支持多dex,所以ART虚拟机可以很大提升APP的冷启动速度。
除了这个优点外,ART还提升了GC速度,提供功能更全面的Debug特性,但是缺点也就是APK安装速度慢,占用的空间多。
来个一图流
 +
+
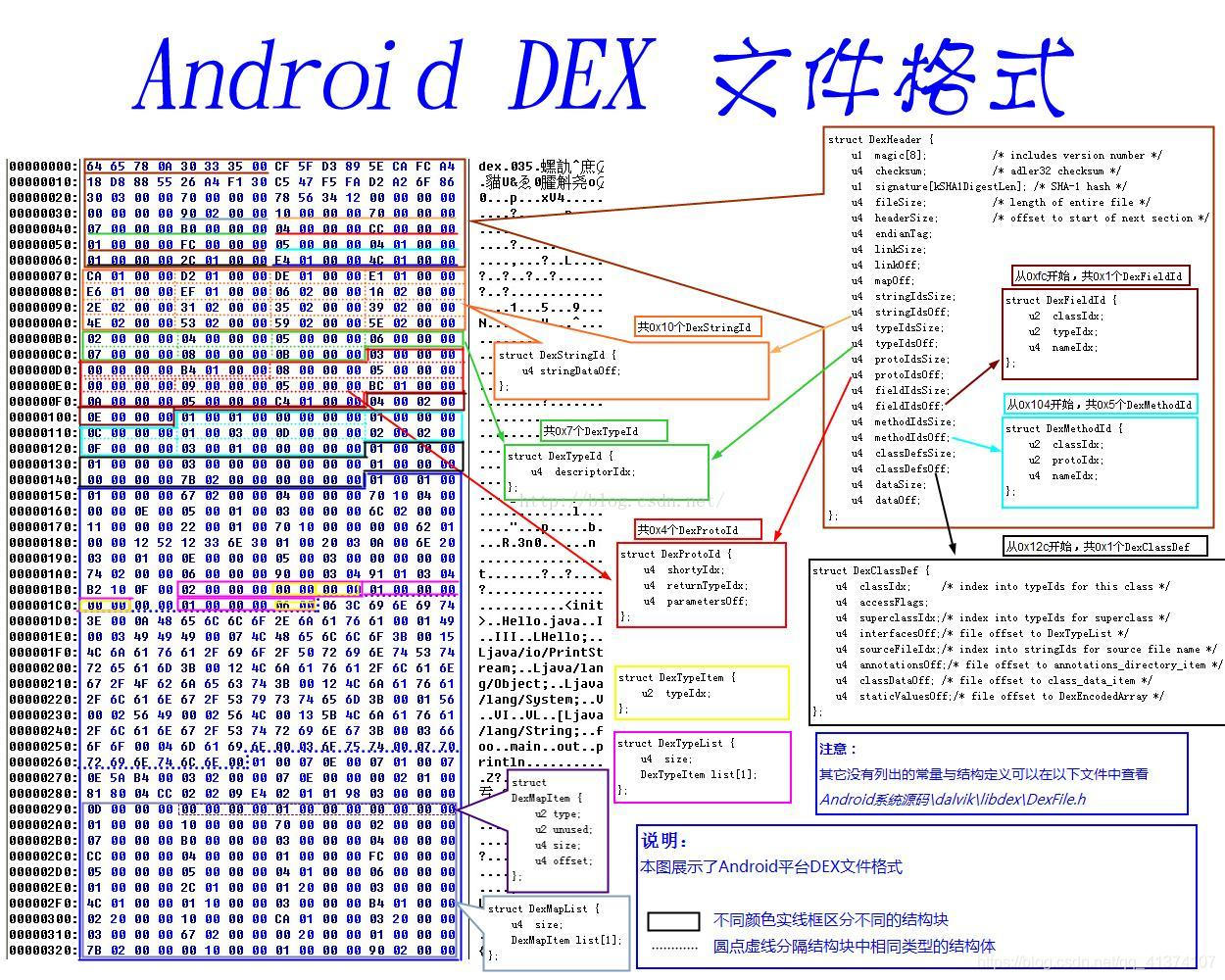
DEX文件头较简单,不涉及编码等,真好
同时还有源码看http://androidxref.com/9.0.0_r3/xref/dalvik/libdex/DexFile.h
010也有提供模板,看得也挺舒服的
DEX单独编译
其实比较简单
就是用Java8的jdk组件中的javac编译成.class,然后再用Android套件中的dx工具
中间采了个坑,安卓套件的路径有空格SB Windows一直没识别出来:
1 | |
这样就得到了一个dex
生成图
分层

DEX HEADER
1 | |
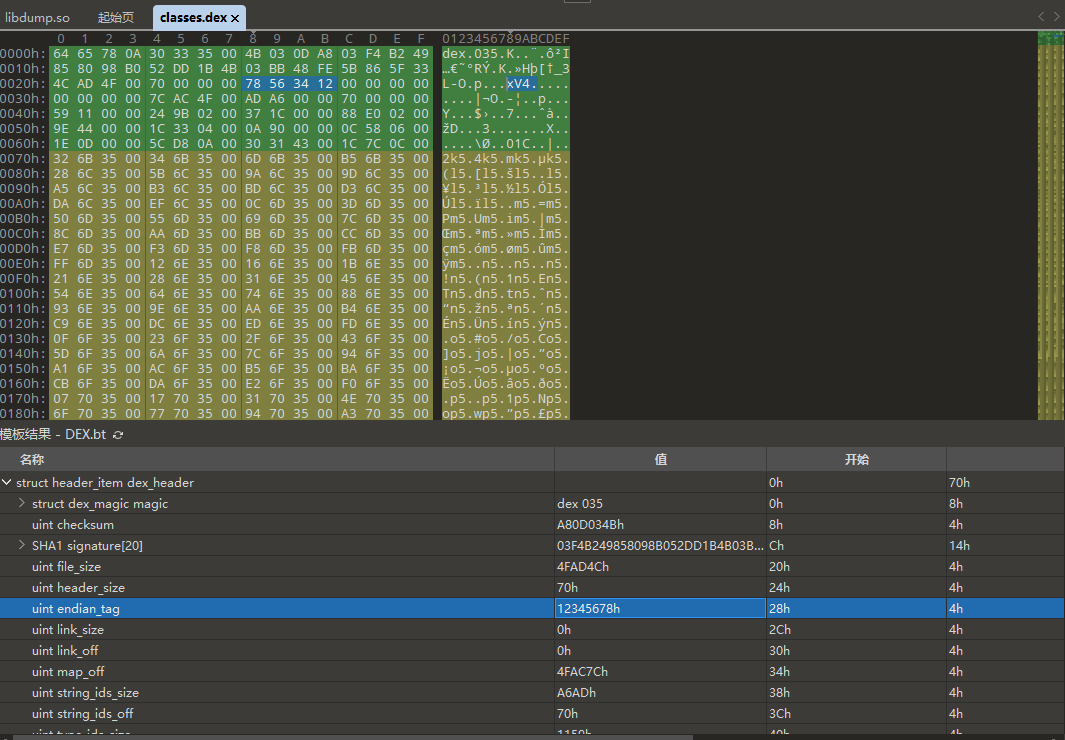
Dex里面很多数据是小端序。包括前面的0x78563412,如下图:
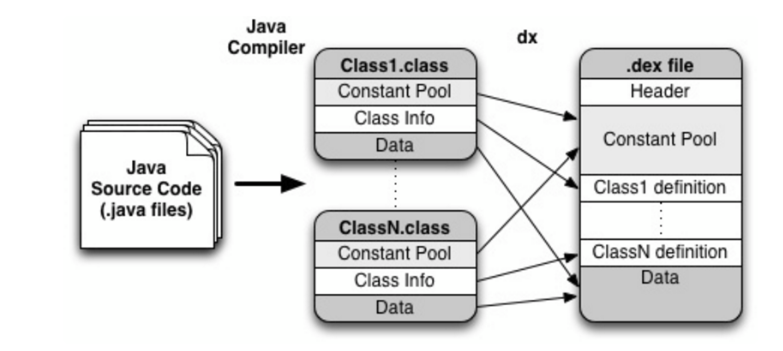
Magic value
魔数字段,格式如"dex\n035\x00",其中035表示结构的版本
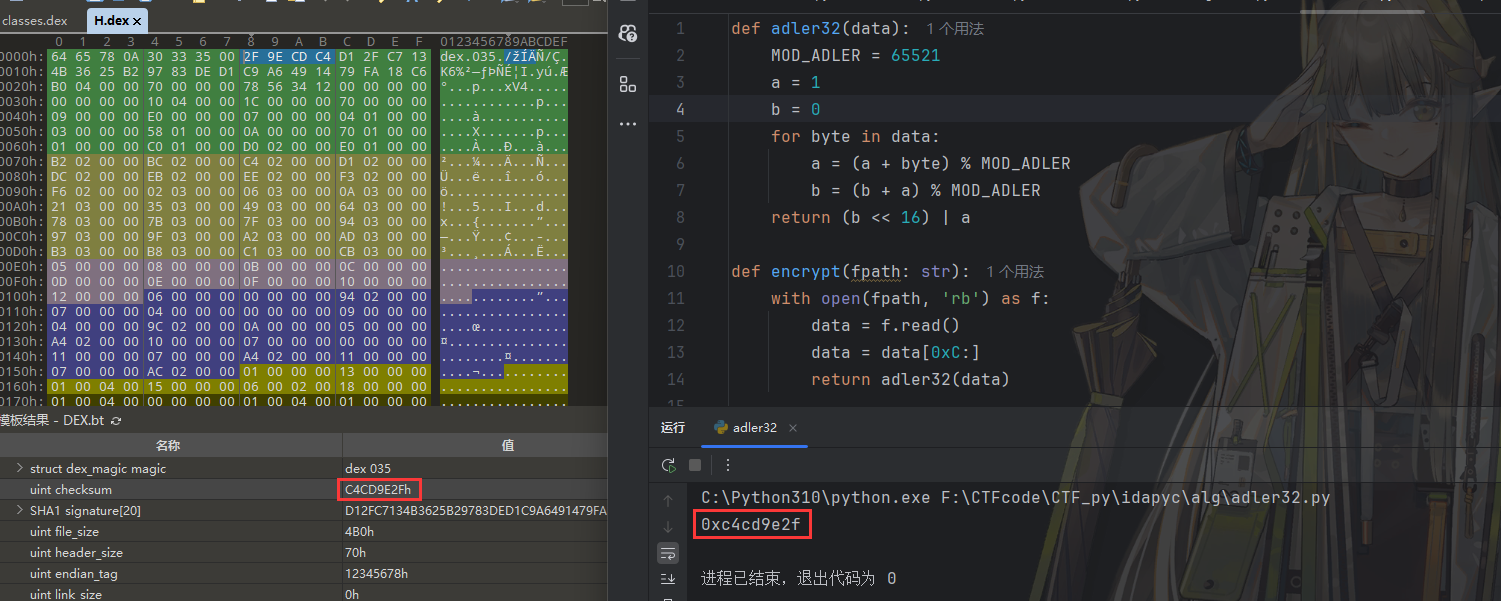
checksum
dex文件的校验和,它可以判断dex文件是否损坏或者篡改,占用4个字节,注意这里是采用小字节序的编码方式。
计算方式为去除 magic 、 checksum 以外的文件部分作 alder32 算法得到的校验值,用于判断 DEX 文件是否被篡改。
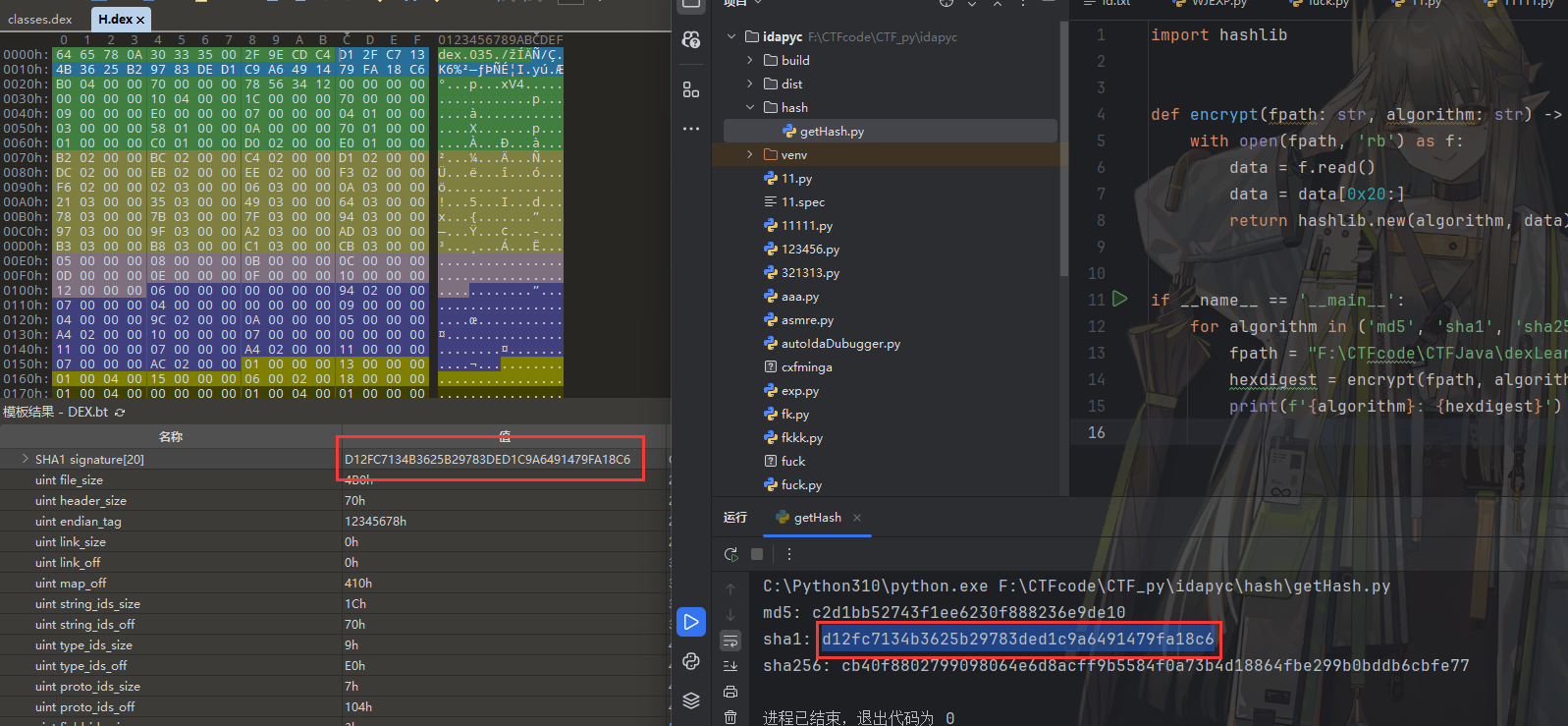
signature
SHA-1签名,计算方式为去掉magic value、checksum和signature的dex文件进行SHA-1计算,即去掉头0x20个字节
fileSize
整个dex文件的大小
headerSize
头大小,一般来说0x70
endian_tag
用于标记 DEX 文件是大端表示还是小端表示。由于 DEX 文件是运行在 Android 系统中的,所以一般都是小端表示, 这里具体的值就2个,
表示字节序,,标准的.dex格式采用小段字节序,但具体实现可能会选择执行字节交换,所以这个改变就由这个tag来判断。
,这个值也是恒定值 0x12345678。
link_size & link_off
2个字段指定了链接段的大小和文件偏移,linkSize为0表示为静态链接,此时LinkOff也是0。
map_off
这个字段表示DexMapList的文件偏移
string_ids_size & string_ids_off
这2个字段指定了dex文件中所有用到的字符串的个数和位置偏移,注意这里指的是位置偏移,而不是真正的字符串值。
偏移会指向string_id_list表,表里储存的是字符串的偏移地址。
type_ids_size & type_ids_off
类的类型的数量和位置偏移
偏移的位置指向一个type表,表的每个单元内容是前面string_id_list的下标,对应的字符串就是对应的type
proto_ids_size & proto_ids_off
方法原型的个数和位置偏移
对应的数据还是和type字符串类似
field_ids_size & field_ids_off
表示java文件中字段的信息的个数和位置偏移
method_ids_size & method_ids_off
dex文件中的方法个数和偏移
class_defs_Size & class_defs_off
类定义的
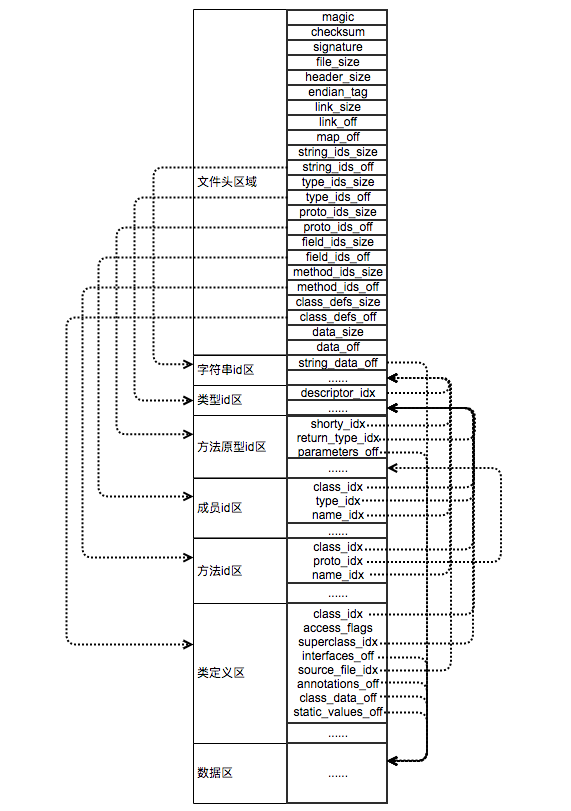
下面再看一次dex结构图
id区
id 区存储着字符串,type,prototype,field, method 资源的真正数据在文件中的偏移量,我们可以根据 id 区的偏移量去找到该 id 对应的真实数据
string_ids
这个区块是一个偏移量列表,每个偏移量对应了一个真正的字符串资源,每个偏移量占32位。我们可以通过偏移量找到对应的实际字符串数据。具体格式如下:
| 名称 | 格式 | 描述 |
|---|---|---|
| string_data_off | uint | 从文件的开头到此项的字符串数据的偏移量 |
1 | |
最终这个偏移的位置应该是落在数据区的。找到这个偏移量的位置后,根据下面的格式就可以读取出这个字符串资源的具体数据:
| 名称 | 格式 | 描述 |
|---|---|---|
| utf16_size | uleb16 | 字符串的解码长度,使用UTF-16编码(?真是utf16,吗,看起来像是单byte,但是010的模板说是utf16) |
| data | ubyte[] | 具体的字符串内容,len=utf16_size |
1 | |
type_ids
这个区块是一个索引列表,索引的值对应字符串id区域偏移量列表中的某一项。数据格式如下:
| 名称 | 格式 | 描述 |
|---|---|---|
| descriptor_idx | uint | 这个类型的字符串描述在字符串id区域的索引 |
1 | |
流程大概为:读取descriptor_idx,从string_ids中读取string_data_off,从data里面读取对应的string
下面是示例,后面的流程都相同,后面就不演示:
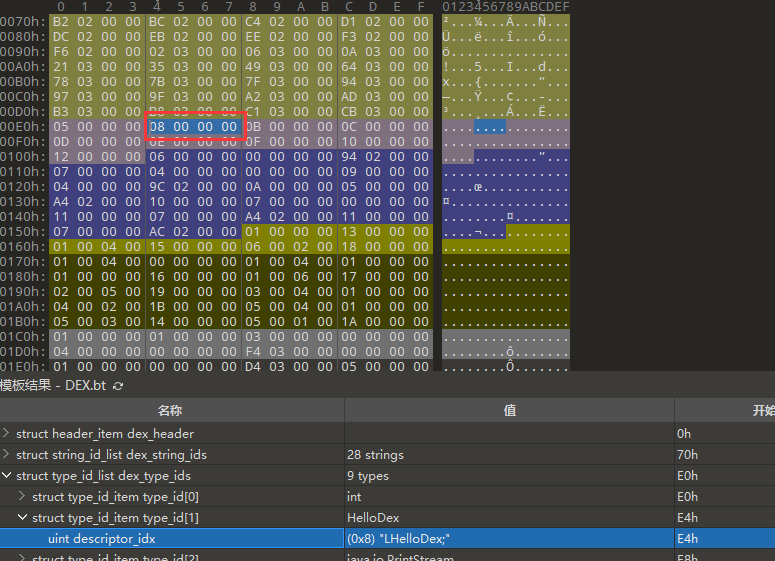
这里是0x8,于是去string_ids中找:
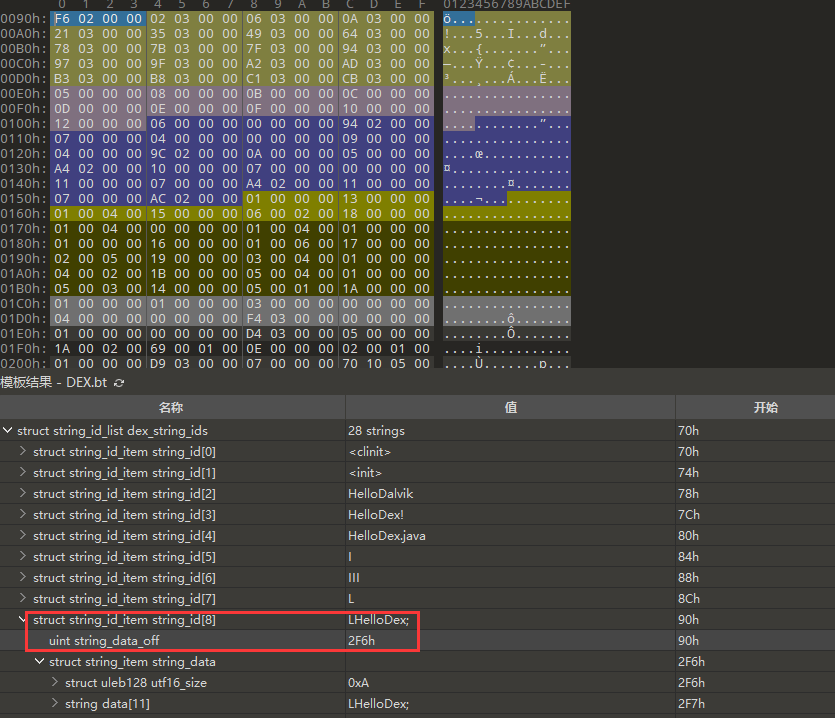
再去data找:
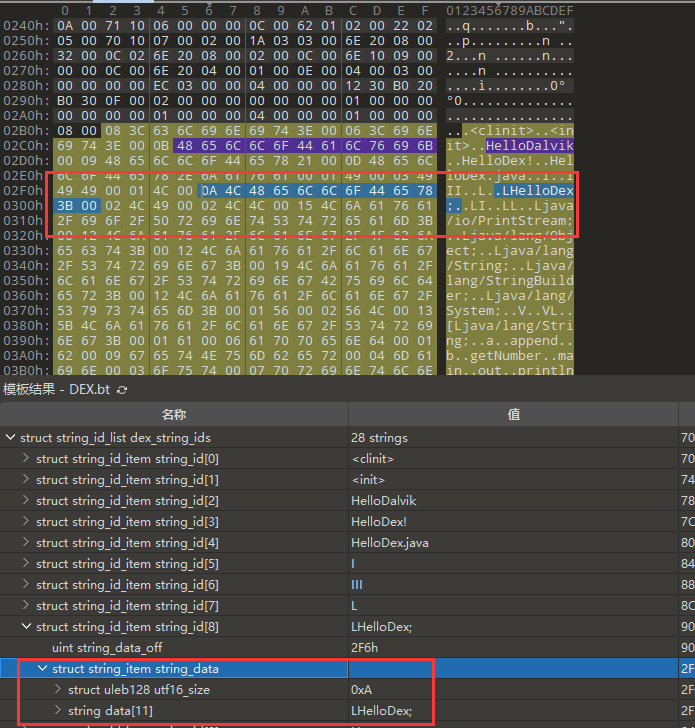
proto_ids
这个区块是一个方法原型 id 列表,数据格式为:
| 名称 | 格式 | 描述 |
|---|---|---|
| shorty_idx | uint | 一个字符串id区的索引,这个索引对应的字符串id列表项中的偏移量存储的字符串是这个方法原型的短格式描述符。 |
| return_type_idx | uint | 这个方法原型的返回值类型在类型id列表中索引 |
| parameters_off | uint | 这个方法原型的参数值列表类型数据的偏移量。0代表没有参数 |
1 | |

field_ids
这个区块存储着原型 id 列表,数据格式为:
| 名称 | 格式 | 描述 |
|---|---|---|
| class_idx | ushort | 这个成员所在的类在类型id列表中的索引 |
| type_idx | ushort | 这个成员的类型在类型id列表中的索引 |
| name_idx | uint | 这个成员的名字在字符串id列表的索引 |
1 | |
method_ids
这个区块存储着方法 id 列表,数据格式为:
| 名称 | 格式 | 描述 |
|---|---|---|
| class_idx | ushort | 这个方法所在的类在类型id列表中的索引 |
| proto_idx | ushort | 这个方法的原型在方法原型id列表中的索引 |
| name_idx | uint | 这个方法的名字在字符串id列表的索引 |
1 | |
class_ids
| 名称 | 格式 | 描述 |
|---|---|---|
| class_idx | uint | 这个类在类型id列表中的索引 |
| access_flags | uint | 这个类的访问标记(如:public,final等) |
| superClass_idx | uint | 这个类的父类在类型id列表中的索引,如果此类没有父类(即它是根类,例如 Object),该值为常量值 NO_INDEX |
| interfaces_off | uint | 这个类使用的接口列表在文件中的偏移量; 如果没有就为0,该偏移量(如果为非零值)应该位于 data 区段。 |
| source_file_idx | uint | 这个类的源码文件的文件名称在字符串id列表中的索引 若该值为特殊值 NO_INDEX,以表示缺少这种信息。 |
| annotations_off | uint | 这个类的注解数据在文件中的偏移量。 |
| class_data_off | uint | 这个类的具体数据在文件中的偏移量 |
| static_values_off | uint | 静态成员的初始值列表在文件中的偏移量 |
1 | |
access_flag
具体数值请参考相关定义
https://source.android.google.cn/docs/core/runtime/dex-format?hl=zh-cn#access-flags
LEB128:("Little-Endian Base 128"), 表示任意有符号或无符号整数的可变长度编码.
uleb128中每个字节只有7位为有效位,如果第一个字节的最高位为1,表示LEB128需要使用第二个字节,如果第二个字节的最高位为1,表示会使用到第三个字节,以此类推,直到最后的字节最高位为0,当然LEB128最多使用到5个字节,如果读取5个字节后下一个字节最高位仍为1,则表示该Dex文件无效,Dalvik虚拟机遇到这种情况是直接报错。
EXP:
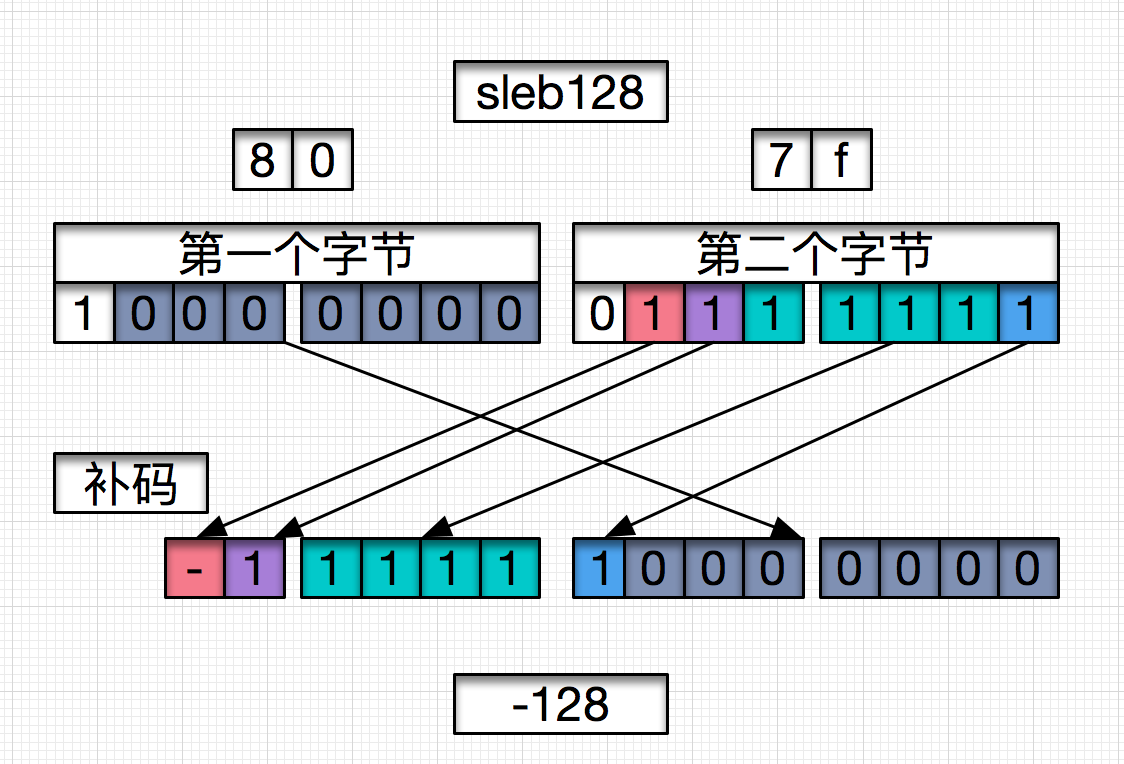
LEB128编码格式中还有一种特殊的编码格式uleb128p1这种编码格式的值为
uleb128的值加上1。通常将这个值转换为
uleb128格式,然后这个值的基础上减去一,得到的值就是uleb128p1格式的值。
NO_INDEX:https://source.android.google.cn/docs/core/runtime/dex-format?hl=zh-cn#no-index
常量
NO_INDEX用于表示索引值不存在。
NO_INDEX的选定值可表示为uleb128p1编码中的单个字节。
uint NO_INDEX = 0xffffffff; // == -1 if treated as a signed int
参考资料
https://zhuanlan.zhihu.com/p/66800634
https://juejin.cn/post/7078164422761381918
https://blog.csdn.net/qq_41374107/article/details/104636659
https://tech.youzan.com/qian-tan-android-dexwen-jian/
https://chan-shaw.github.io/2020/03/17/DEX%E6%96%87%E4%BB%B6%E8%A7%A3%E6%9E%90/
https://source.android.google.cn/docs/core/runtime/dex-format?hl=zh-cn#class-def-item