pwnnotes-stackOverflow
Stack Overflow
Basic
ret2shellcode
需要找一段可写可执行的段
在新版内核当中引入了较为激进的保护策略,程序中通常不再默认有同时具有可写与可执行的段,这使得传统的 ret2shellcode 手法不再能直接完成利用。
ret2syscall
简单说:把对应获取 shell 的系统调用的参数放到对应的寄存器中,那么我们在执行 int 0x80 就可执行对应的系统调用。比如说这里我们利用如下系统调用来获取 shell:
1 | |
其中,该程序是 32 位,所以我们需要使得:
- 系统调用号,即 eax 应该为 0xb
- 第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。
- 第二个参数,即 ecx 应该为 0
- 第三个参数,即 edx 应该为 0
比如用:
1 | |
去筛选一下,找方便的地址可以去控制寄存器
简单的实现
1 | |
ret2libc
就是找libc的基值,然后通过偏移找到system 和 /bin/sh字符串
然后栈溢出
Middle
ret2csu
在 64 位程序中,函数的前 6 个参数是通过寄存器传递的,但是大多数时候,我们很难找到每一个寄存器对应的 gadgets。 这时候,我们可以利用 x64 下的 __libc_csu_init 中的 gadgets。
ret2reg
- 查看溢出函返回时哪个寄存值指向溢出缓冲区空间
- 然后反编译二进制,查找 call reg 或者 jmp reg 指令,将 EIP 设置为该指令地址
- reg 所指向的空间上注入 Shellcode (需要确保该空间是可以执行的,但通常都是栈上的)
BROP
(Blind ROP) 于 2014 年由 Standford 的 Andrea Bittau 提出,其相关研究成果发表在 Oakland 2014,其论文题目是 Hacking Blind,下面是作者对应的 paper 和 slides, 以及作者相应的介绍
基本思路
在 BROP 中,基本的遵循的思路如下
- 判断栈溢出长度
- 暴力枚举
- Stack Reading
- 获取栈上的数据来泄露 canaries,以及 ebp 和返回地址。
- Blind ROP
- 找到足够多的 gadgets 来控制输出函数的参数,并且对其进行调用,比如说常见的 write 函数以及 puts 函数。
- Build the exploit
- 利用输出函数来 dump 出程序以便于来找到更多的 gadgets,从而可以写出最后的 exploit。
栈溢出长度
直接从 1 暴力枚举即可,直到发现程序崩溃。
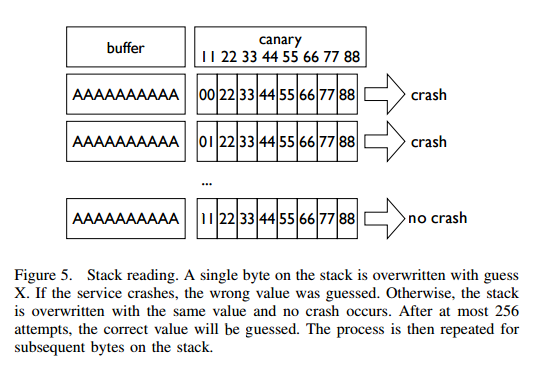
Stack Reading
如下所示,这是目前经典的栈布局
1 | |
canary 本身可以通过爆破来获取,但是如果只是愚蠢地枚举所有的数值的话,显然是低效的。
需要注意的是,攻击条件 2 表明了程序本身并不会因为 crash 有变化,所以每次的 canary 等值都是一样的。所以我们可以按照字节进行爆破。正如论文中所展示的,每个字节最多有 256 种可能,所以在 32 位的情况下,我们最多需要爆破 1024 次,64 位最多爆破 2048 次。
突然发现自己好像不需要学会BROP。。有空再摸
High
太高端了,我就了解一下。。
ret2dlresolve
原理
在 Linux 中,程序使用 _dl_runtime_resolve(link_map_obj, reloc_offset) 来对动态链接的函数进行重定位。那么如果我们可以控制相应的参数及其对应地址的内容是不是就可以控制解析的函数了呢?答案是肯定的。这也是 ret2dlresolve 攻击的核心所在。
具体的,动态链接器在解析符号地址时所使用的重定位表项、动态符号表、动态字符串表都是从目标文件中的动态节 .dynamic 索引得到的。所以如果我们能够修改其中的某些内容使得最后动态链接器解析的符号是我们想要解析的符号,那么攻击就达成了。
ret2VDSO
VDSO(Virtual Dynamically-linked Shared Object)
具体来说,它是将内核态的调用映射到用户地址空间的库。那么它为什么会存在呢?这是因为有些系统调用经常被用户使用,这就会出现大量的用户态与内核态切换的开销。通过 vdso,我们可以大量减少这样的开销,同时也可以使得我们的路径更好。这里路径更好指的是,我们不需要使用传统的 int 0x80 来进行系统调用,不同的处理器实现了不同的快速系统调用指令
- intel 实现了 sysenter,sysexit
- amd 实现了 syscall,sysret
当不同的处理器架构实现了不同的指令时,自然就会出现兼容性问题,所以 linux 实现了 vsyscall 接口,在底层会根据具体的结构来进行具体操作。而 vsyscall 就实现在 vdso 中。
SROP
利用sigreturn去实现控制
攻击原理
仔细回顾一下内核在 signal 信号处理的过程中的工作,我们可以发现,内核主要做的工作就是为进程保存上下文,并且恢复上下文。这个主要的变动都在 Signal Frame 中。但是需要注意的是:
- Signal Frame 被保存在用户的地址空间中,所以用户是可以读写的。
- 由于内核与信号处理程序无关 (kernel agnostic about signal handlers),它并不会去记录这个 signal 对应的 Signal Frame,所以当执行 sigreturn 系统调用时,此时的 Signal Frame 并不一定是之前内核为用户进程保存的 Signal Frame。