ELF文件
简介
ELF (Executable and Linkable Format)文件,也就是在 Linux 中的目标文件,主要有以下三种类型
- 可重定位文件(Relocatable File),包含由编译器生成的代码以及数据。链接器会将它与其它目标文件链接起来从而创建可执行文件或者共享目标文件。在 Linux 系统中,这种文件的后缀一般为
.o。 - 可执行文件(Executable File),就是我们通常在 Linux 中执行的程序。
- 共享目标文件(Shared Object File),包含代码和数据,这种文件是我们所称的库文件,一般以
.so结尾。一般情况下,它有以下两种使用情景 - 链接器(Link eDitor, ld)可能会处理它和其它可重定位文件以及共享目标文件,生成另外一个目标文件。
- 动态链接器(Dynamic Linker)将它与可执行文件以及其它共享目标组合在一起生成进程镜像。
文件格式
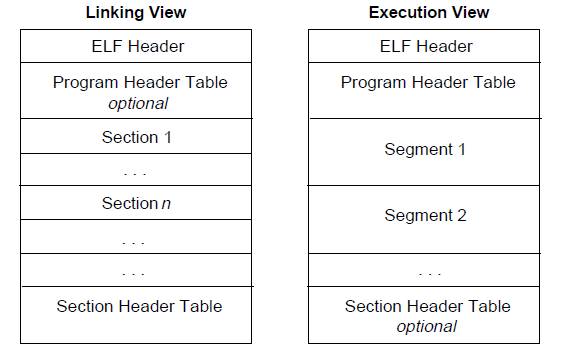
首先,我们来关注一下链接视图。
文件开始处是ELF 头部( ELF Header),它给出了整个文件的组织情况。
如果程序头部表(Program Header Table)存在的话,它会告诉系统如何创建进程。用于生成进程的目标文件必须具有程序头部表,但是重定位文件不需要这个表。
节区 (Section) 部分包含在链接视图中要使用的大部分信息:指令、数据、符号表、重定位信息等等。
节区头部表(Section Header Table)包含了描述文件节区的信息,每个节区在表中都有一个表项,会给出节区名称、节区大小等信息。用于链接的目标文件必须有节区头部表,其它目标文件则无所谓,可以有,也可以没有。
下图为链接视图比较形象的展示:

数据形式
| 名称 | 长度 | 对齐方式 | 用途 |
|---|---|---|---|
| Elf32_Addr | 4 | 4 | 无符号程序地址 |
| Elf32_Half | 2 | 2 | 无符号半整型 |
| Elf32_Off | 4 | 4 | 无符号文件偏移 |
| Elf32_Sword | 4 | 4 | 有符号大整型 |
| Elf32_Word | 4 | 4 | 无符号大整型 |
| unsigned char | 1 | 1 | 无符号小整型 |
ELF Header
ELF Header 描述了 ELF 文件的概要信息,利用这个数据结构可以索引到 ELF 文件的全部信息,数据结构如下:
1 | |
e_ident
该变量给出了用于解码和解释文件中与机器无关的数据的方式。
这个数组对于不同的下标的含义如下:
| 宏名称 | 下标 | 目的 |
|---|---|---|
| EI_MAG0 | 0 | 文件标识 |
| EI_MAG1 | 1 | 文件标识 |
| EI_MAG2 | 2 | 文件标识 |
| EI_MAG3 | 3 | 文件标识 |
| EI_CLASS | 4 | 文件类 |
| EI_DATA | 5 | 数据编码 |
| EI_VERSION | 6 | 文件版本 |
| EI_PAD | 7 | 补齐字节开始处 |
E.P.
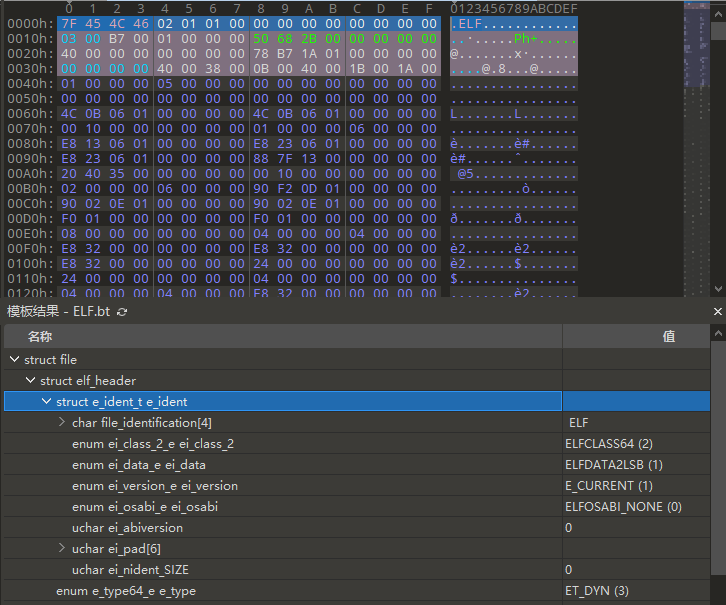
e_ident[EI_MAG0]到e_ident[EI_MAG3],即文件的头4个字节,被称作“魔数”,标识该文件是一个ELF目标文件。
| 名称 | 值 | 位置 |
|---|---|---|
| ELFMAG0 | 0x7f | e_ident[EI_MAG0] |
| ELFMAG1 | ‘E’ | e_ident[EI_MAG1] |
| ELFMAG2 | ‘L’ | e_ident[EI_MAG2] |
| ELFMAG3 | ‘F’ | e_ident[EI_MAG3] |
e_ident[EI_CLASS], 标识文件的类型或容量:
| 名称 | 值 | 意义 |
|---|---|---|
| ELFCLASSNONE | 0 | 无效类型 |
| ELFCLASS32 | 1 | 32位文件 |
| ELFCLASS64 | 2 | 64位文件 |
e_ident[EI_DATA]字节给出了目标文件中的特定处理器数据的编码方式。下面是目前已定义的编码:
| 名称 | 值 | 意义 |
|---|---|---|
| ELFDATANONE | 0 | 无效数据编码 |
| ELFDATA2LSB | 1 | 小端 |
| ELFDATA2MSB | 2 | 大端 |
e_ident[EI_PAD]给出了e_ident中未使用字节的开始地址。这些字节被保留并置为0;处理目标文件的程序应该忽略它们。如果之后这些字节被使用,EI_PAD的值就会改变。
e_type
e_type 标识目标文件类型。
| 名称 | 值 | 意义 |
|---|---|---|
| ET_NONE | 0 | 无文件类型 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享目标文件 |
| ET_CORE | 4 | 核心转储文件 |
| ET_LOPROC | 0xff00 | 处理器指定下限 |
| ET_HIPROC | 0xffff | 处理器指定上限 |
e_machine
这一项指定了当前文件可以运行的机器架构。
| 名称 | 值 | 意义 |
|---|---|---|
| EM_NONE | 0 | 无机器类型 |
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel 80386 |
| EM_68K | 4 | Motorola 68000 |
| EM_88K | 5 | Motorola 88000 |
| EM_860 | 7 | Intel 80860 |
| EM_MIPS | 8 | MIPS RS3000 |
e_version
标识目标文件的版本。
| 名称 | 值 | 意义 |
|---|---|---|
| EV_NONE | 0 | 无效版本 |
| EV_CURRENT | 1 | 当前版本 |
e_entry
这一项为系统转交控制权给 ELF 中相应代码的虚拟地址。如果没有相关的入口项,则这一项为0。
e_phoff
这一项给出程序头部表在文件中的字节偏移(Program Header table OFFset)。如果文件中没有程序头部表,则为0。
e_shoff
这一项给出节头表在文件中的字节偏移( Section Header table OFFset )。如果文件中没有节头表,则为0。
e_flags
这一项给出文件中与特定处理器相关的标志,这些标志命名格式为EF_machine_flag。
e_ehsize
这一项给出 ELF 文件头部的字节长度(ELF Header Size)。
e_phentsize
这一项给出程序头部表中每个表项的字节长度(Program Header ENTry SIZE)。每个表项的大小相同。
e_phnum
这一项给出程序头部表的项数( Program Header entry NUMber )。因此,e_phnum 与 e_phentsize 的乘积即为程序头部表的字节长度。如果文件中没有程序头部表,则该项值为0
e_shentsize
这一项给出节头的字节长度(Section Header ENTry SIZE)。一个节头是节头表中的一项;节头表中所有项占据的空间大小相同。
e_shnum
这一项给出节头表中的项数(Section Header NUMber)。因此, e_shnum 与 e_shentsize 的乘积即为节头表的字节长度。如果文件中没有节头表,则该项值为0。
e_shstrndx
这一项给出节头表中与节名字符串表相关的表项的索引值(Section Header table InDeX related with section name STRing table)。如果文件中没有节名字符串表,则该项值为SHN_UNDEF。关于细节的介绍,请参考后面的“节”和“字符串表”部分。
Program Header Table
概述
Program Header Table 是一个结构体数组,每一个元素的类型是 Elf32_Phdr,描述了一个段或者其它系统在准备程序执行时所需要的信息。
其中,ELF 头中的 e_phentsize 和 e_phnum 指定了该数组每个元素的大小以及元素个数。一个目标文件的段包含一个或者多个节。
程序的头部只有对于可执行文件和共享目标文件有意义。
可以说,Program Header Table 就是专门为 ELF 文件运行时中的段所准备的。
Elf32_Phdr 的数据结构如下:
1 | |
每个字段的说明如下
| 字段 | 说明 |
|---|---|
| p_type | 该字段为段的类型,或者表明了该结构的相关信息。 |
| p_offset | 该字段给出了从文件开始到该段开头的第一个字节的偏移。 |
| p_vaddr | 该字段给出了该段第一个字节在内存中的虚拟地址。 |
| p_paddr | 该字段仅用于物理地址寻址相关的系统中, 由于”System V”忽略了应用程序的物理寻址,可执行文件和共享目标文件的该项内容并未被限定。 |
| p_filesz | 该字段给出了文件镜像中该段的大小,可能为0。 |
| p_memsz | 该字段给出了内存镜像中该段的大小,可能为0。 |
| p_flags | 该字段给出了与段相关的标记。 |
| p_align | 可加载的程序的段的 p_vaddr 以及 p_offset 的大小必须是 page 的整数倍。该成员给出了段在文件以及内存中的对齐方式。如果该值为 0 或 1 的话,表示不需要对齐。除此之外,p_align 应该是 2 的整数指数次方,并且 p_vaddr 与 p_offset 在模 p_align 的意义下,应该相等。 |
段类型 p_type
| 名字 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。 |
| PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果 p_memsz 大于 p_filesz,“剩余”的字节都要被置为0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照 p_vaddr 的升序排列。 |
| PT_DYNAMIC | 2 | 此类型段给出动态链接信息。 |
| PT_INTERP | 3 | 此类型段给出了一个以 NULL 结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。 |
| PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。 |
| PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合ABI标准。 |
| PT_PHDR | 6 | 该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。此外,只有程序头部表是程序的内存映像的一部分时,它才会出现。如果此类型段存在,则必须在所有可加载段项目的前面。 |
| PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。 |
基地址 Base Address
程序头部的虚拟地址可能并不是程序内存镜像中实际的虚拟地址。通常来说,可执行程序都会包含绝对地址的代码。为了使得程序可以正常执行,段必须在相应的虚拟地址处。另一方面,共享目标文件通常来说包含与地址无关的代码。这可以使得共享目标文件可以被多个进程加载,同时保持程序执行的正确性。尽管系统会为不同的进程选择不同的虚拟地址,但是它仍然保留段的相对地址,因为地址无关代码使用段之间的相对地址来进行寻址,内存中的虚拟地址之间的差必须与文件中的虚拟地址之间的差相匹配。内存中任何段的虚拟地址与文件中对应的虚拟地址之间的差值对于任何一个可执行文件或共享对象来说是一个单一常量值。这个差值就是基地址,基地址的一个用途就是在动态链接期间重新定位程序。
可执行文件或者共享目标文件的基地址是在执行过程中由以下三个数值计算的
- 虚拟内存加载地址
- 最大页面大小
- 程序可加载段的最低虚拟地址
要计算基地址,首先要确定可加载段中 p_vaddr 最小的内存虚拟地址,之后把该内存虚拟地址缩小为与之最近的最大页面的整数倍即是基地址。根据要加载到内存中的文件的类型,内存地址可能与 p_vaddr 相同也可能不同。