软件测试笔记
前言
这门课是真的什么都找不到,概念又多,但是你看看概念又知道该怎么搞。。。。烦的一。。。
模型驱动测试设计
发现一个软件失败的四个必要条件
- 可达性(Reachability):测试用例必须到达程序中包含故障的位置
- 影响(Infection):程序的故障部分被执行后会造成不正确的程序状态
- 传播(Propagation):被影响后的状态会传播且导致不正确的输出或者错误的最终状态
- 揭示性(Revealability):测试者能够观察到程序最终状态中不正确的部分
覆盖准则
定义测试需求的规则和过程的集合
- 涵盖所有语句
- 涵盖所有功能需求
可以简化为四种结构
- 输入域
- 图
- 逻辑表达式
- 语法描述
测试自动化
测试自动化
使用软件来控制测试用例的执行、实际输出和预期输出的比较、先验条件的设置,以及其他的测试控制和测试报告功能
- 降低成本
- 减少人为错误
- 使回归测试变得更加容易
可测性
为了评判测试准则是否达标,系统或组件在测试准则建立和测试用例性能提升方面所能提供的便利程度
两个实际问题很大程度上决定了可测性
- 如何向软件提供测试数据
- 如何观察测试执行的结果
可观察性
观察程序行为的难易程度。程序行为包括输出、程序对运行环境、软件和硬件的影响
- 嵌入式软件的可观察性很低
可控性
向程序提供所需输入的难易程度。程序输入包括数据值、操作和行为
- 来自键盘的输入很容易控制
- 来自硬件传感器或者分布式软件的输入很难控制
许多可观察性和可控性问题是用仿真来解决的
测试用例的结构
测试用例值:在待测软件上完成测试执行所需要的输入值
前缀值:将待测软件置于合适状态以接收测试用例值的必要输入
后缀值:测试用例值发送之后,待测软件仍然需要的输入
验证值:查看测试用例值结果所需要的值
退出值:终止程序或使程序回到一个稳定状态所需要的值或命令输入
预期结果:当软件的行为符合预期时,软件在测试用例中应产生的结果
测试用例:包括必要的测试用例值、前缀值、后缀值和预期结果,以便完整地执行和评估待测软件
测试集:测试用例的集合
可执行的测试脚本:处于一种可以在待测软件上自动运行和生成报告的形式的测试用例
测试优先
传统方法在最开始时尝试定义所有正确的行为
敏捷方法根据一组具体的测试用例来重定义正确性
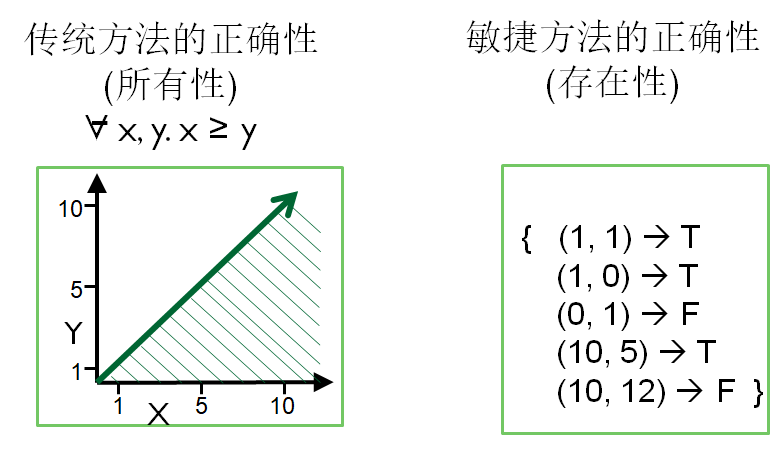
测试装置的正确性验证
- 测试必须自动化
- 测试自动化是测试驱动开发的先决条件
- 每个测试都必须包含一个能够评估该测试是否正确执行的测试oracle
- 测试代替了需求
- 测试必须是高质量,并且能快速运行
- 每次变更软件时都会运行测试
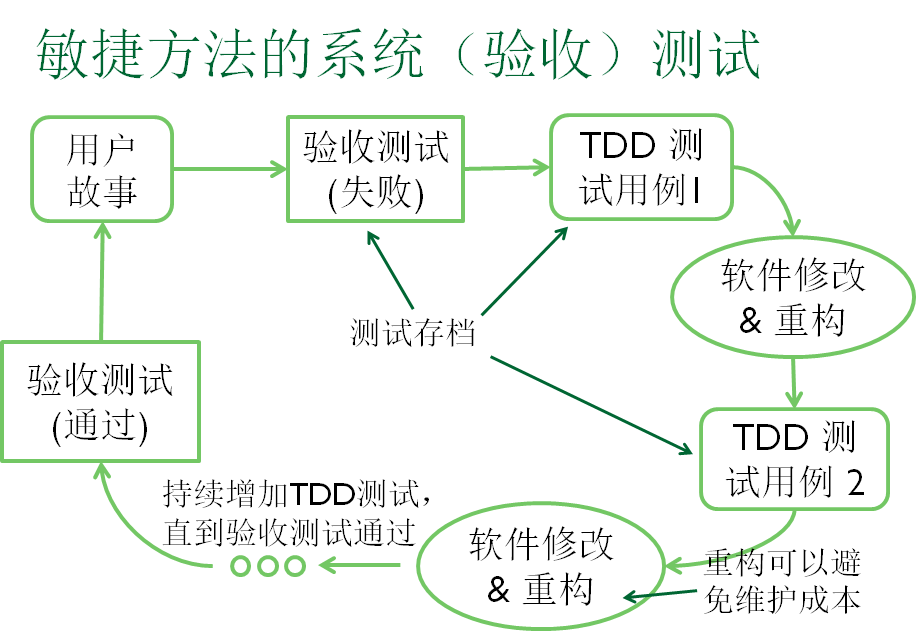 TDD测试[1]
TDD测试[1]
设计测试
使用建模和准则
- 对输入域建模以设计测试用例
- 用图形、逻辑、语法来对软件行为建模
- 内置的完成机制
- 要求掌握离散数学
基于准则的设计测试
- 测试需求:软件工件中测试用例必须满足或覆盖的指定元素
- 覆盖准则:一个或者一组决定了在一个测试用例要覆盖的测试需求的规则
可以简化为四种结构
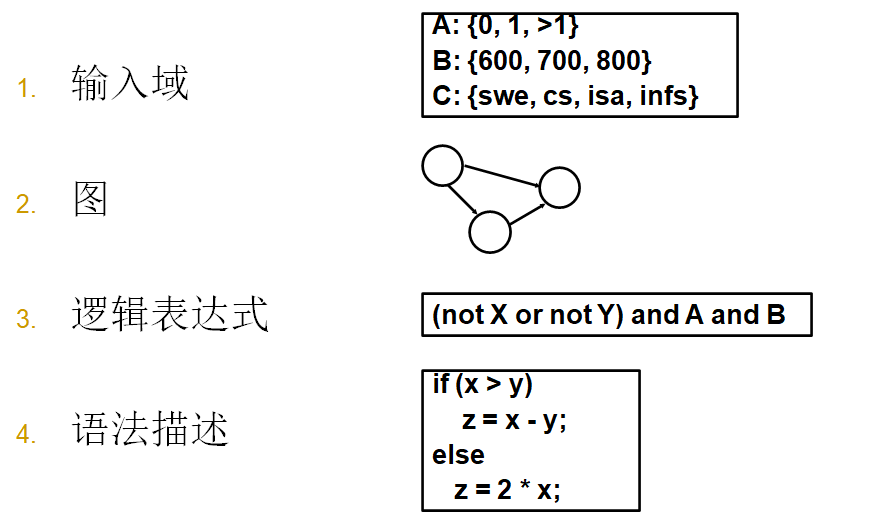
上述四种结构可以从很多软件工件中提取
- 图能从UML用例图、有限状态机、源代码等中提取
- 逻辑表达式能从源代码的决策、迁移的guard、用例图的条件等中提取
覆盖
给定一个覆盖准则C所包含的测试需求集TR,测试用例集T覆盖准则C,当且仅当对TR中的每一个测试需求tr,T中至少存在一个测试用例t满足tr
- 100%覆盖在实际中是不可能的
不可行的测试需求:不能被满足的测试需求
- 满足测试需求的用例值不存在,如Dead code
- 对大多数准则,检测需求是否不可行是不可判定的
极小/最小覆盖准则
极小测试用例集
给定一个测试需求集TR和一个满足所有测试需求的测试用例集T,如果从T中移除任意单个的测试用例会导致T不再满足所有的测试需求,那么T就是极小的(没有冗余的)
最小测试用例集
给定一个测试需求集TR和一个满足所有测试需求的测试用例集T,如果不存在满足所有测试需求的更小的测试用例集,那么T就是最小的
- 检测一个测试用例集是否极小的是容易的
- 检测一个测试用例集是否最小的是不可判定的
覆盖程度
给定一个测试需求集TR和一个测试用例集T,T满足TR中的测试需求数和TR的需求总数的比例
准则覆盖
测试准则C1包含测试准则C2,当且仅当满足C1的所有测试用例集也满足C2
- 假设覆盖准则C1包含覆盖准则C2,且有在程序P上的测试用例集T1满足C1,在程序P上的测试用例集T2满足C2
- T1一定满足C2
- T2不一定满足C1
- T2能揭示的故障T1不一定能揭示
基于准则测试的好处
最大化“收益”
- 更少的测试用例能更有效地发现故障
全面且极小重叠的测试用例集
软件工件的可追溯性
准则是从特定软件工件推导出来的
对回归测试提供内置支持
停止规则
- 可以提前知道有多少测试用例
便于自动化
好的覆盖准则的特征
- 能够很容易地自动产生测试需求
- 能够很高效地生成测试用例值
- 能够发现尽可能多的软件故障
输入空间划分
本质上,所有测试都是从待测软件的输入空间中选择(有限)元素
- 即使是小程序,输入空间可能巨大甚至无穷
输入空间划分:根据程序输入的逻辑划分关系来直接划分输入空间
优点
- 可应用于多个级别的测试
- 单元、集成、系统
- 容易上手,无需自动化
- 易于调节,以便获得更多或更少的测试
- 不需要了解实现细节
- 只需了解输入空间
输入域
程序的输入域包含该程序的所有可能输入
输入域定义为输入参数可能拥有的全部测试值
方法参数
非局部变量
从文件中读取的数据
用户输入
代表程序当前状态的对象
输入空间划分:将输入域划分为区块,并从每个区块中至少选择一个(代表性)值
域及其划分
存在域D,域D上的划分q;
划分q定义一个区块集合\(B_q=\{b_1,b_2,b_3,....\}\)
划分必须满足两个属性:
- 区块间必须两两不相交(互斥性)
- 区块的并能够覆盖域D(完备性)
输入域划分(IDM)
五个步骤
- 识别可测试的功能
- 每个(公有)方法都是一个可测试的功能
- 同个类中的方法通常具有相同的特性
- 识别所有参数
- 通常较简单,甚至是机械的
- 完整性很重要
- 对输入域建模
- 输入域是由参数确定
- 输入域的结构是根据特征来定义的
- 应用测试准则选择值的组合
- 每个测试输入都有一个值对应于每个参数
- 每个特征都有一个区块
- 选择所有组合通常是不可行的
- 覆盖准则允许选择子集
- 将组合值细化为测试输入
两种方法
基于接口的输入域建模
独立分析每个参数
简单的建模技术,主要依赖于语法
一些域和语义信息将不被使用
- 可能导致IDM不全面
忽略参数之间的关系
基于功能的输入域建模
识别与待测系统所设计的功能相对应的特征
可以结合专业领域和语义知识
可以利用参数之间的关系
建模是基于需求,而不是实现
同一个参数可能出现在多个特征中,因此很难将值转换为测试用例
需要更多的设计工作
设计特征
特征候选集
- 前置条件和后置条件
- 变量之间的关系(是否别名等)
- 变量与特殊值的关系(零、null、空等)
- 缺失的因素(影响出现执行的因素)
注:不应该使用程序源代码,程序源代码应与图或逻辑准则一起使用
选择区块和测试值
关键:如何设计划分和选择代表性测试值
划分通常直接从特征设计开始,且一起完成
识别代表性测试值的策略
- 有效值、无效值和特殊值
- 对某些区块进行子划分
- 探索区块边界
- 表示“正常使用”的值(大众路径)
- 尝试平衡每个特征中的区块数
- 检查完整性(遗留区块)和互斥性(重叠区块)
使用多个IDM
某些程序可能使用几十个甚至几百个参数
- 采用分而治之,构建几个小型IDM
- 软件不同部分可以采用不同要求进行测试
- 不同的IDM有重叠是可以接受的
- 同一变量可能出现在多个IDM中
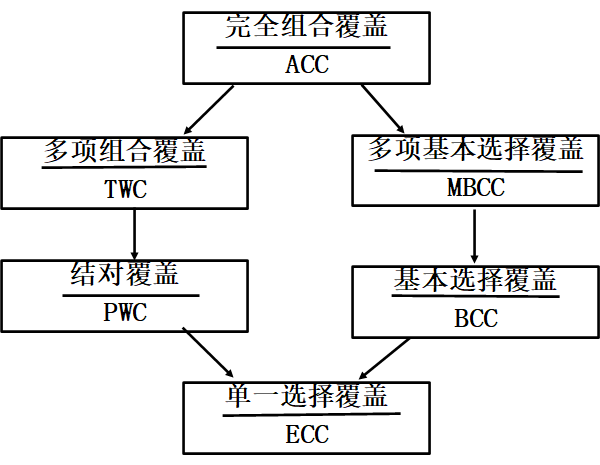
组合策略准则(!!)
完全组合覆盖(ACC)
All Combination Coverage:必须使用来自所有特征区块的所有组合
即选择所有的组合
测试用例的数量是每个划分的所有区块数的乘积: \[ \Pi _{i=1}^{Q}(B_i)\\ A_{Q}^{Q} \]
单一覆盖准则(ECC)
Each Choice Coverage: 每个特征每个区块的一个测试值必须在至少一个测试用例中出现
即每个测试值都至少用一次
测试用例的数量是划分区块数中的最大值 \[ MAX_{i=1}^{Q}(B_i) \] 例子:
假如ECC的测试需求是:
{A1, B1, C1, A2, B2, C2, A3, B3, C3, A4, B4, C4}
那测试用例是:
{A1, B1, C1}、{A2, B2, C2}、{A3, B3, C3}、{A4, B4, C4}
结对覆盖(PWC)
Pair-Wise Coverage:每个特征对每个区块中的一个测试值必须要与其他特征的每个区块中的值进行组合
即两两配对,不在配对组合之中的,可以随意取值。
测试用例的数量是划分区块数中的最大两个数的乘积 \[ (MAX_{i=1}^{Q}(B_i))*(MAX_{j=1,j!=i}^{Q}(B_j)) \] 例子:
| 特征划分 | b1 | b2 | b3 | b4 |
|---|---|---|---|---|
| A | A1 | A2 | A3 | A4 |
| B | B1 | B2 | B3 | B4 |
| C | C1 | C2 | C3 | C4 |
抽象标签下PWC的测试需求:
(A1,B1), (A1,B2), (A1,B3), (A1,B4), (A1,C1), (A1,C2), (A1,C3), (A1,C4), (A2,B1) … (A4,C4),(B1,C1) … (B4,C4)
所以生成的测试用例
A1, B1, C1 A1, B2, C2 A1, B3, C3 A1, B4, C4 A2, B1, C2 A2, B2, C3 A2, B3, C4 A2, B4, C1 A3, B1, C3 A3, B2, C4 A3, B3, C1 A3, B4, C2 A4, B1, C4 A4, B2, C1 A4, B3, C2 A4, B4, C3
多项组合覆盖(TWC)
T-Wise Coverage: 所有由t个特征构成的组合的每个区块中的测试值都必须进行组合
就是PWC的威力加强版,PWC是两两组合,这个是一组有t个,t个之外的数据随意。
测试用例的数量是划分区块数中最大t个数的乘积
基本选择覆盖(BCC)
- 测试者可能意识到某些值非常重要
- 引入程序中少量但由关键的领域知识
Base Choice Coverage: 每个特征选取一个区块作为基本选择。使用每个特征的基本选择构成一个基本测试用例。剩余的测试用例保持基本测试用例中除了一个基本选择常量之外的所有值,并使用对应特征中的每个非基本选择来代替那个基本选择
就是确定一个基本用例,然后每次只在基本用例的基础上改一个,直到测试完所有的值。
测试用例集包括一个基本用例+其他区块一个用例 \[ 1+\sum_{i=1}^Q(B_i-1) \] 例子:
还是PWC中的ABC三种输入。
设基本测试用例为:(A1,B1,C1)
那么测试用例如下:
(A1, B1, C2) (A1, B2, C1) (A2, B1, C1) (A1, B1, C3) (A1, B3, C1) (A3, B1, C1) (A1, B1, C4) (A1, B4, C1) (A4, B1, C1)
多项基本选择覆盖(MBCC)
Multiple Base Choice Coverage: 每个特征选取一个或多个区块作为基本选择。使用每个特征的每个基本选择至少一次,构成一些基本测试用例。剩余的测试用例保持基本测试用例中除了一个基本选择常量之外的所有值,并使用对应特征中的每个非基本选择来代替那个基本选择
假设M个基本测试用例,每个特征有\(m_i\)个基本选择,则测试用例的数量为 \[ M+\sum_{i=1}^{Q}(M*(B_i-m_i)) \] 例子:
假设基本测试用例为(A1,B1,C1), (A2,B2,C2)
测试用例如下:
(A1, B1, C1) : (A1, B1, C3) (A1, B3, C1) (A3, B1, C1) (A1, B1, C4) (A1, B4, C1) (A4, B1, C1)
(A2, B2, C2): (A2, B2, C3) (A2, B3, C2) (A3, B2, C2) (A2, B2, C4) (A2, B4, C2) (A4, B2, C2)
组合策略的包含关系
特征之间的约束
有些区块的组合是不可行的
这些表示为区块间的约束
两种常见的约束类型
来自一个特征的一个区块不能与来自另一个特征的某个区块组合
来自一个特征的一个区块只能与来自另一个特征的某个区块组合
约束的处理依赖于所使用的准则
ACC,PWC,TWC:丢弃不可行的组合对
BCC,MBCC:改变基本选择使得测试需求变得更可行
如果IDM有太多的约束,这很有可能是结构上的问题,需要重新设计IDM
图覆盖
概述
图是测试中最常用的结构
图来自许多不同来源和类型的软件工件
控制流程图
设计结构
有限状态机和状态图
用例图
基于图覆盖的测试就是以某种方式“覆盖”图
图的定义
- 节点集合N,N不为空
- 初始节点集合N0,N0 ⊆N,且不为空
- 终止节点集合Nf,Nf ⊆N ,且不为空
- 边集合E, E ⊆N × N
- (ni,nj), ni为前序节点, nj后继节点
路径
- 路径:一个节点序列\([n_1, n_2, …, n_M]\)
- 每对邻近节点\((n_i, n_i+1)\)属于边集合\(E,1≤i≤M-1\)
- 长度:边的数目
- 单一节点可看作是长度为0的路径
- 子路径:路径p的子序列称为p的子路径
- 环:开始节点和结束节点相同的路径
测试路径
测试路径:一条开始于起始节点、结束于终止节点长度可能为零的路径
测试路径代表测试用例的执行
有些测试路径可以由许多测试用例执行
某些测试路径不能由任何测试用例执行
单入单出图(SESE):单一起始节点且单一终止节点
图覆盖准则
- 测试需求:描述测试路径的需求
- 测试准则:定义测试需求的规则
- 图覆盖准则:给定一个测试准则C所包含的测试需求集TR,测试用例集T覆盖准则C,当且仅当对TR中的每一个测试需求tr,测试路径集合path(T)中至少存在一条测试路径p满足tr
- 结构化覆盖准则(控制流覆盖准则)
- 数据流覆盖准则
结构化覆盖准则
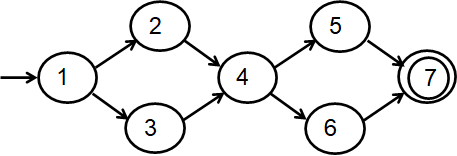
节点覆盖(NC)
Node Coverage: 测试用例集T满足图G的节点覆盖,当且仅当N中每个语法上可达的节点n,path(T)中都有一条路径p访问n
简写:TR包含G中每个可达节点
节点覆盖也称语句覆盖
边覆盖(EC)
Edge Coverage: TR包含G中每条长度小于等于1的可达路径
- 稍强于节点覆盖
- 小于等于1:考虑只有一个节点没有边的图
- 不然EC不包含NC
- NC和EC主要差别体现在没有else的if结构
- 也称分支覆盖
对边覆盖(EPC)
Edge Pair Coverage: TR包含G中每条长度小于等于2的可达路径
- 类似EC,此处使用小于等于2,以包含EC和NC
完全路径覆盖(CPC)
Complete Path Coverage: TR包含G中所有路径
不幸的是,如果图中有环,CPC是不可行的
折中考虑,让测试者指定要覆盖的路径
指定路径覆盖(SPC)
Specified Path Coverage:TR包含一个指定的测试路径集合S
例子

有环图的处理
当图中有环,则有无穷多条的路径,所以CPC是不可行的
由于主观性(随着测试者不同而变化),SPC不是很令人满意
已有的处理方式:
- 1970s:执行环一次
- 1980s:执行每条环一次
- 1990s:执行环0次,1次,多余1次
- 2000s:主路径(游历,顺路,绕路)
简单路径
一条没有任何节点出现多于一次的路径,除了开始节点和结束节点可能相同外
主路径
一条不是其他任何简单路径的子路径的简单路径
主路径覆盖(PPC)
Prime Path Coverage: TR包含G中每条主路径
- 将游历所有长度为0,1,…的路径
- PPC包含NC和EC
- PPC几乎包含EPC,即不包含
- 原因:
- 如果节点n有自循环边,那么EPC要求覆盖[n,n,m]和[m,n,n],其中m和n存在边 [n,n,m]和[m,n,n]都不是简单路径,因而不是主路径
得到一个图的主路径可以参考:
- 从起始节点不进入环到达终止节点
- 从起始节点进入环(终止环节点“前”一个节点)
- 从环节点“后”一个节点出发到达环节点后从环中退出,并到达终止节点
- 环中各个节点自循环
往返路径(SPTC)
Simple Round Trip Coverage: 对于G中所有存在往返路径的可达节点,TR包含至少一条往返路径
完全往返路径(CRTC)
Complete Round Trip Coverage: 对于G中所有存在往返路径的可达节点,TR包含所有往返路径
- 这些准则忽视不在往返路径的节点和边
- SPTC和CRTC都不包含NC、EC或EPC
访问、游历和绕路
主路径不允许有内循环
访问:若节点n存在测试路径p中,则称p访问n
若边e存在测试路径p中,则称p访问e
游历:若路径q是测试路径p的子路径,则称p游历q
顺路游历:测试路径p顺路游历路径q,若q中每条边以同样顺序出现在p中
- 暂时离开路径的某个节点,顺路访问其他节点再回到该节点
绕路游历:测试路径p绕路游历路径q ,若q中每个节点以同样顺序出现在p中
- 暂时离开路径的某个节点,绕路访问其他节点再回到原路径的下一个节点(跳过一条边)
不可行测试需求
不可行测试需求:不能满足的测试需求
不可到达的语句(死代码)
存在矛盾的子路径(X>0 and X<0)
大多数测试准则都存在一些不可行测试需求
当不允许顺路,很多结构化覆盖准则具有更多不可行测试需求
最大限度游历(BET)
Best Effort Touring: (1)不允许顺路条件下,满足尽可能多的测试需求;(2)允许顺路条件下,尽量满足剩下测试需求
数据流覆盖准则
定义:当一个变量的值被存于内存时该变量所在位置(语句)
当获取一个变量的值时该变量所在位置(语句)
定义使用对
- def(n)或def(e):节点n或边e定义的变量集合
- use(n)或use(e):节点n或边e使用的变量集合
- 定义使用对(DU pair):两个位置的组对(li,lj),且存在变量v在li被定义,在lj被使用
- 无重复定义(Def-clear):一条从li到lj的路径关于变量v是无重复定义,若该路径上除li外的任何点或边没有定义v
- 到达:若存在一条从li到lj的路径关于变量v是无重复定义的,则处于li的v的定义能到达处于lj的使用
定义使用路径
一条从变量v的定义到达v的使用、且关于v是无重复定义的简单路径
- du(ni,nj,v):从ni到nj、关于v的定义使用路径集合
- du(ni,v):始于ni、关于v的定义使用路径集合
全定义覆盖(ADC)
All-Defs Coverage: 对每个定义使用路径集合S=du(n,v),TR包含S中至少一条路径d
全使用覆盖(AUC)
All-Uses Coverage: 对每个定义使用路径集合S=du(ni,nj,v),TR包含S中至少一条路径d
全定义使用覆盖(ADUPC)
All-DU-Paths Coverage: 对每个定义使用路径集合S=du(ni,nj,v),TR包含S中每条路径d
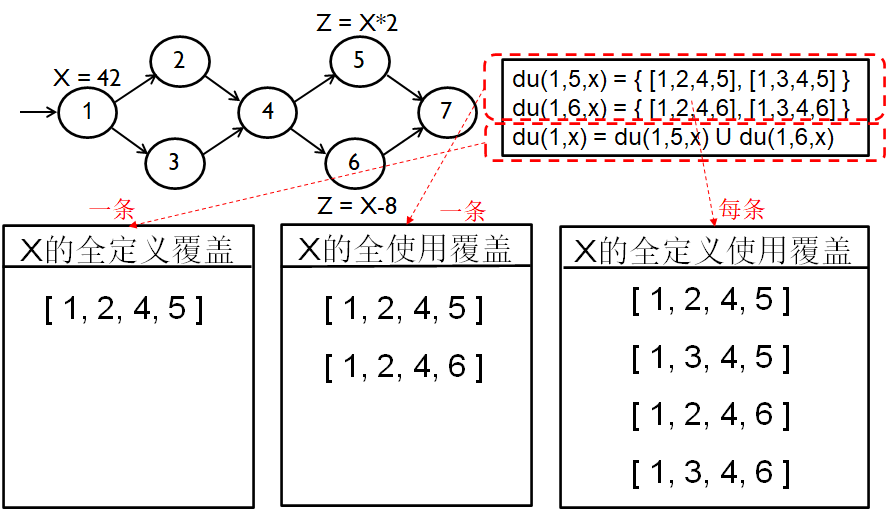
基于源码的图覆盖
最常用的图覆盖准则是针对源代码
图:通常是控制流程图
节点覆盖:执行每条语句(语句覆盖)
边覆盖:执行每条分支(分支覆盖)
数据流覆盖:控制流程图的补充
- 定义:给变量赋值的相关语句
- 使用:使用变量的语句
控制流程图(CFG)
Control,flow graph: 通过描述控制结构对方法的所有可能执行进行建模的图
节点:语句或者语句序列(基本块)
边:控制迁移
基本块:一段最长的可以被顺序执行的语句序列
若第一条语句被执行,则所有语句都被执行
不包括分支和跳转语句
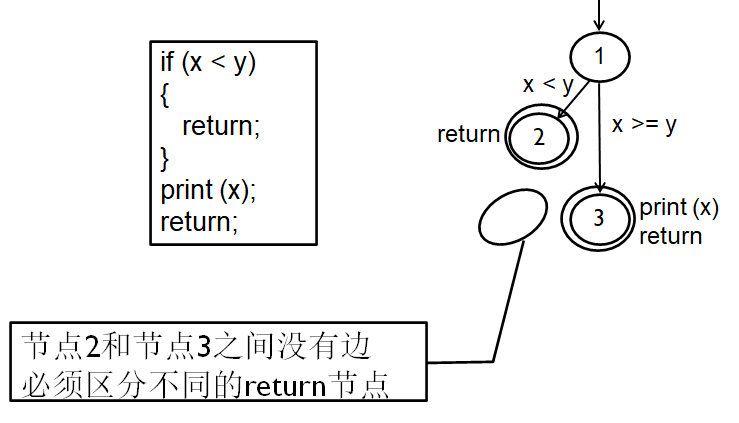
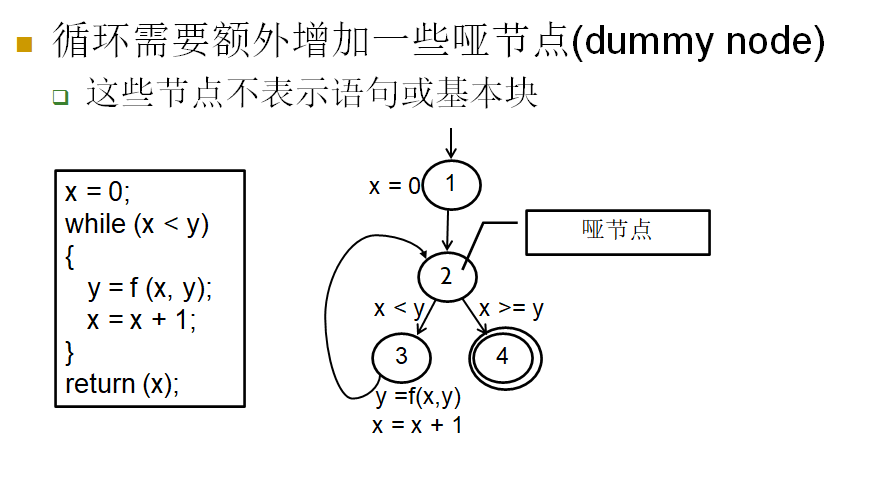
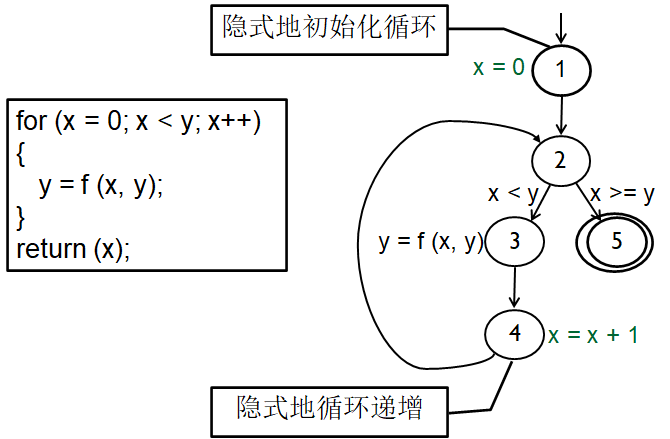
例子:
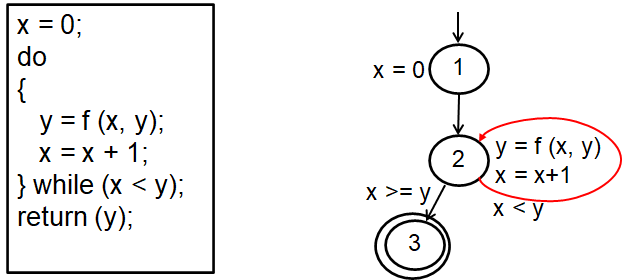
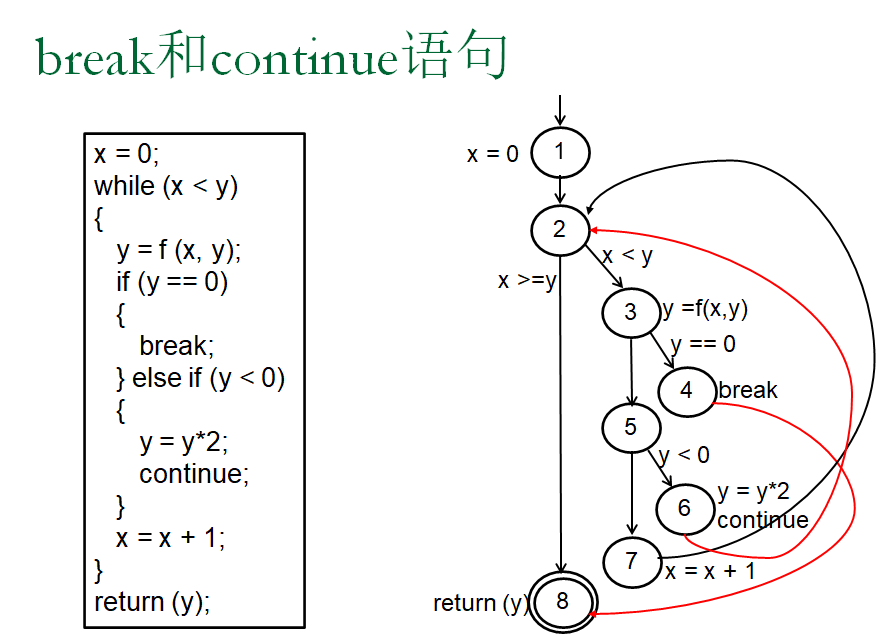
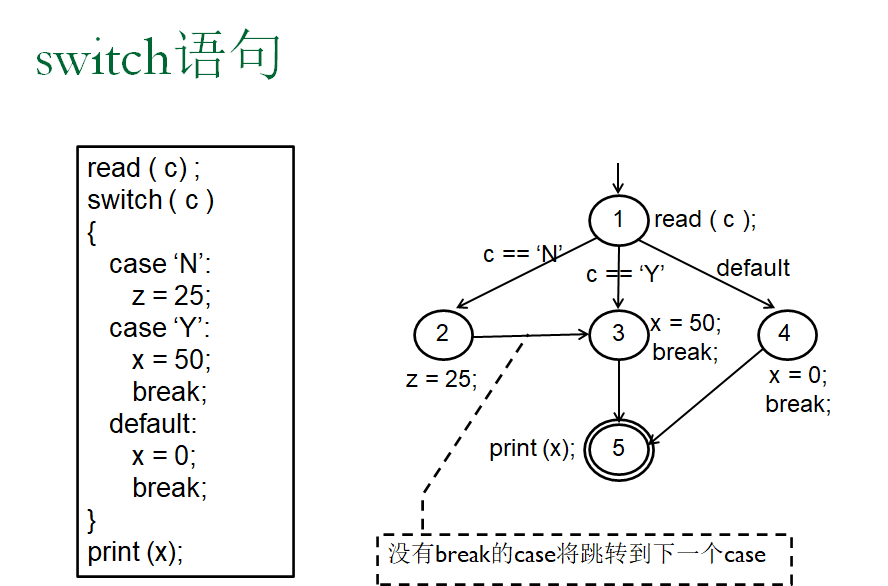
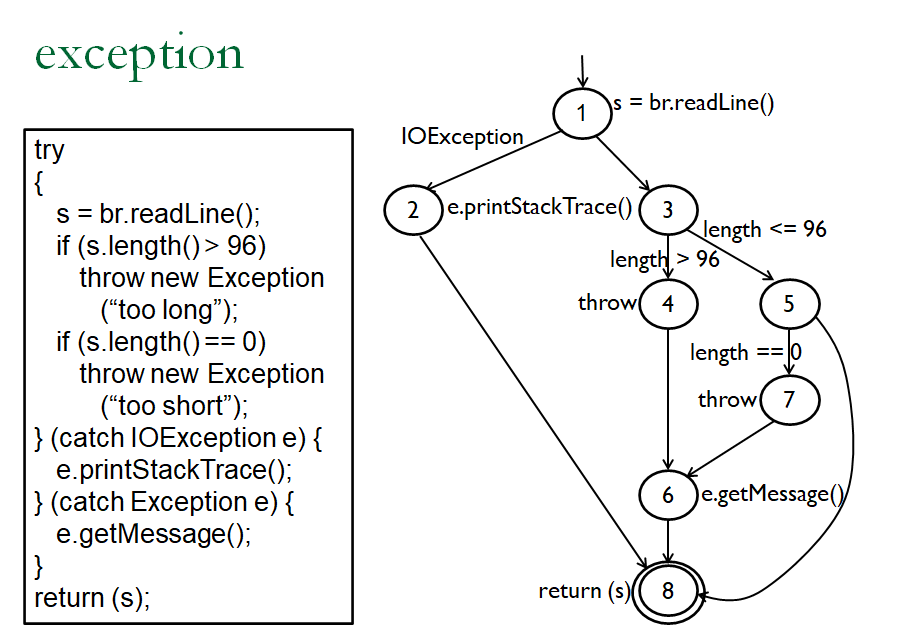
源代码的数据流准则
(和数据流的相似)
定义:
当变量的值被存于内存时该变量所在位置
- x出现在赋值语句的左部(如x=44)
- x是方法的形式参数(方法被调用时隐式定义)
- x是方法的实际参数且在方法体中被修改
- x是程序的输入
使用:
当获取变量的值时该变量所在位置
x出现在赋值语句的右部
x出现在条件判定中
x是方法的实际参数
x是程序的输出
若一对定义使用对出现在同一个节点,该使用称为局部使用
数据流分析一般不考虑局部使用
当定义和使用出现在同一个节点时,只有定义出现在使用之后且该点处于循环中才称它们为定义使用对
逻辑覆盖
语义逻辑准则
测试目的在逻辑表达式的真值表中选择某些子集
逻辑谓词和子句
- 谓词:计算结果为布尔值的表达式
- 谓词可能包括
- 布尔变量
- 非布尔变量的比较(>, <, ==, >=, <=, !=)
- (返回值为布尔值的)函数
- ¬(非)、 ∧(与)、∨(或)
- → (蕴含)、⨁(异或)、⟷(等价)
- 子句:不包含逻辑运算符的谓词
逻辑覆盖准则
一些缩写:
- P:一个谓词集合
- p:P中一个谓词
- C:谓词集合P中的子句的集合
- Cp:谓词p中的子句的集合
- c:C中一个子句
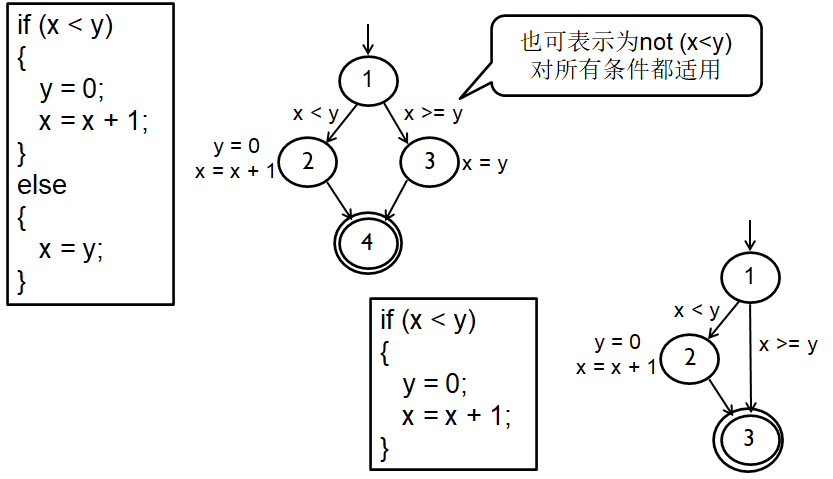
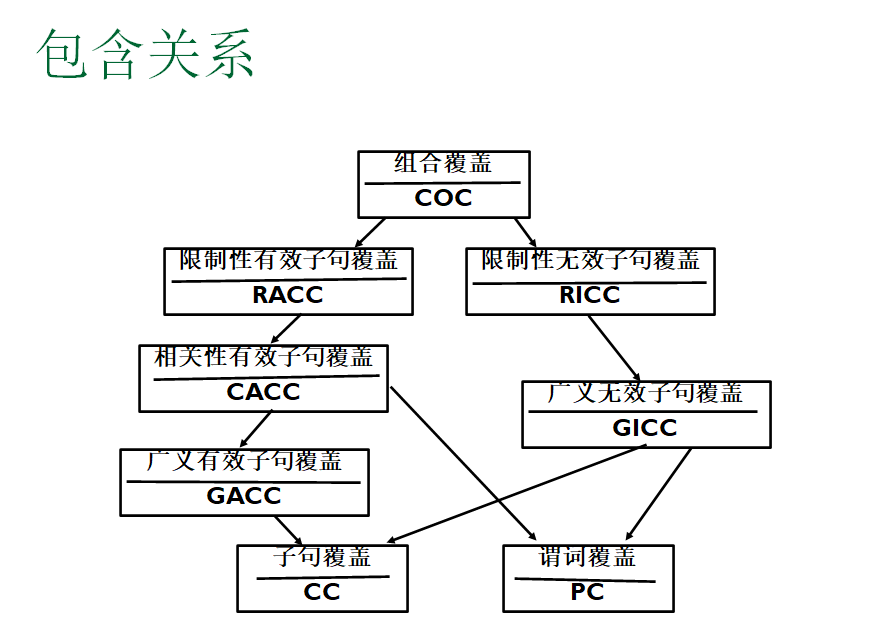
谓词覆盖(PC)
Predicate Coverage: 对于每个p∈P,TR包含两个需求:p的结果为真和p的结果为假
也叫决策覆盖(DC) - Decision Coverage
- 在(控制流程)图上,表现为边覆盖
子句覆盖(CC)
Clause Coverage: 对于每个c∈C,TR包含两个需求:c的结果为真和c的结果为假
n也称“条件覆盖” - Condition Coverage
组合覆盖(CoC)
Combinatorial Coverage: 对于每个p∈P,TR要求Cp中子句结果覆盖真值取值的每种可能组合
- 简单、清晰、容易理解
- 但代码很高:N个子句,则有\(2^N\)个测试用例
有效子句覆盖(ACC)
Active Clause coverage: 对于每个p∈P和每个主子句ci∈Cp,选择次子句cj使得ci决定p。对于每个ci ,TR有两个需求:ci的结果为真和ci的结果为假
有效子句:这个子句能决定谓语的真假时的该子句,其他的子句叫次子句。只要不影响子句的有效子句定位,次子句取值随意。
广义有效子句覆盖(GACC)
General Active Clause coverage: 对于每个p∈P和每个主子句ci∈Cp,选择次子句cj使得ci决定p。对于每个ci ,TR有两个需求:ci的结果为真和ci的结果为假。当ci为真或假的时候,次子句cj的取值不必相同
- 谓语的值可以不管
限制性有效子句覆盖(RACC)
Restricted Active Clause coverage: 对于每个p∈P和每个主子句ci∈Cp,选择次子句cj使得ci决定p。对于每个ci ,TR有两个需求:ci的结果为真和ci的结果为假。当ci为真或假的时候,次子句cj的取值必须相同
- 和GACC相比,RACC就是次子句要每次相同,谓语的值可以不管。
相关性有效子句约束(CACC)
Correlated Active Clause coverage: 对于每个p∈P和每个主子句ci∈Cp,选择次子句cj使得ci决定p。对于每个ci ,TR有两个需求:ci的结果为真和ci的结果为假。次子句cj的取值必须使得主子句ci取一种值时p的结果为真,而取另外一种值时p的结果为假
- RACC相比,次子句的取值一定使得主子句决定谓语p的值。
无效子句覆盖(ICC)
Inactive Clause coverage: 对于每个p∈P和每个主子句ci∈Cp,选择次子句cj使得ci不能决定p。对于每个ci ,TR有四个需求:
(1)ci的结果为真并且p的结果为真; (2)ci的结果为假并且p的结果为真; (3)ci的结果为真并且p的结果为假; (4)ci的结果为假并且p的结果为假;
- 有效子句覆盖准则确保主子句影响谓词
- 相反,无效子句覆盖确保主子句不影响谓词
广义无效子句覆盖(GICC)
General Inactive Clause coverage: 次子句cj在这些情况下的取值可以不同
限制性无效子句覆盖(RICC)
Restricted Inactive Clause coverage: 当ci为真或假的时候,次子句cj的取值必须相同,即(1)和(2)次子句cj的取值必须相同,(3)和(4)也一样
不可行需求
考虑谓词(a > b ∧ b > c) ∨ c > a
- (a > b)=true, (b>c)=true, (c>a)=true是不可行的
类似图覆盖准则,需要识别不可行需求
- 不可判定问题
两种方案
直接忽略
寻找在一个包含的覆盖准则中所对应的测试需求,如使用CACC可行的测试需求来代替RACC中不可行的测试需求(类似最大限度游历)
让子句决定谓词
对简单谓词,次子句的赋值比较容易
直接定义的方式
\(p_{c=true}\):将p中c的每个出现替换成true
\(p_{c=false}\):将p中c的每个出现替换成false
给次子句赋值,只需求解
- \(p_c=p_{c=true} ⨁p_{c=false}\)
\(p_c\)描述了c的取值决定p的条件
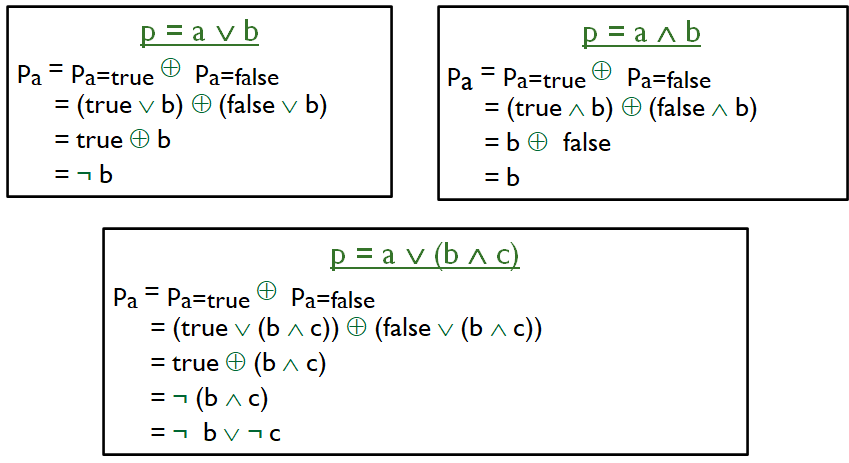
变量重复
- 不管谓词的形式如何,生成测试用例是相同的
无效主子句的次子句赋值

真值表方式
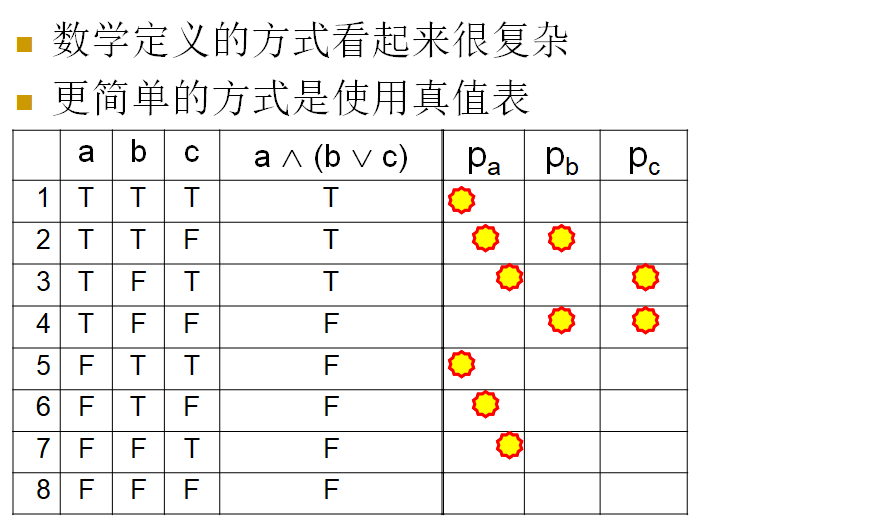
语法逻辑覆盖准则
语义逻辑覆盖准则可以不考虑谓词的形式
既是优点也是缺点
不同形式可能也有影响,如短路求值
语法逻辑准则侧重于逻辑谓词的形式
比语义准则更好
相对更难理解和使用
析取范式

- 任何逻辑表达式都存在与之等值的析取范式
蕴含项覆盖(IC)
Implicant Coverage: 给定谓词\(f\)及其否定的\(\overline{f}\)的DNF(析取范式),对于\(f\) 和\(\overline{f}\)的每个蕴含项,TR要求该项的取值为真
- IC相对较弱:
- 单独测试每个蕴含项比较困难
- DNF有多种形式
极小DNF

唯一真值点(UTP)
给定蕴含项,唯一真值点(UTP)是使得该项为真且其余蕴含项为假的赋值
一个唯一真值点的测试用例只关注一个蕴含项
多项唯一真值点覆盖(MUTP)
给定谓词f的极小DNF,对于f中每个蕴含项i,选择唯一真值点使得不在i中的子句的取值包括真和假
例子:

近似假值点(NFP)
给定f的蕴含项i及其子句c,近似假值点(NFP)是使得f为假、但改变c的取值(其它子句的取值保持不变)则使得i为真(因而f也为真)的赋值
在近似假值点,c决定f(有效子句)
唯一真值点-近似假值点配对覆盖(CUTPNFP)
Corresponding Unique True Point and Near False Point Pair Coverage: 给定谓词f的极小DNF,对于f中每个蕴含项i的每个字c,TR包括i的唯一真值点和i中c的近似假值点,且这两点的区别只在于c的取值
- CUTPNFP包含限制性有效子句覆盖(RACC)
例子:

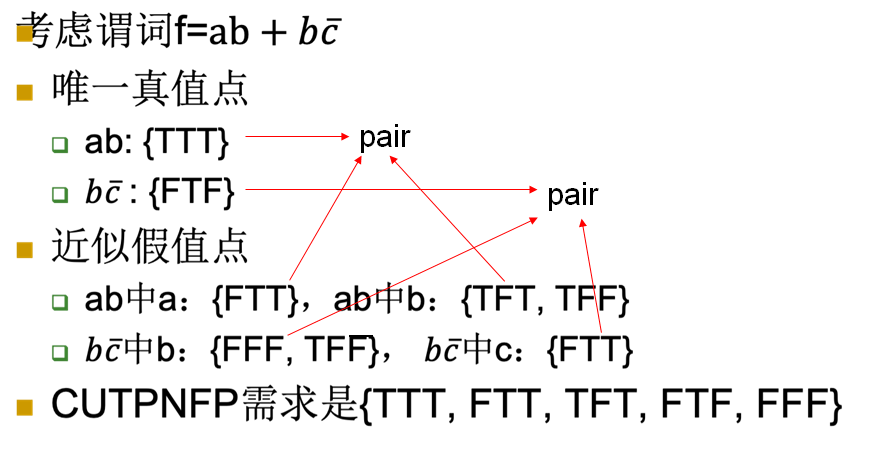
- MUTP ⊄ CUTPNFP
多项近似假值点覆盖(MNFP)
给定谓词f的极小DNF,对于f中每个蕴含项i的每个字c,选择近似假值点使得不在i中的子句的取值包括真和假

- TDD测试用例是指在测试驱动开发(Test-Driven Development,TDD)中,开发人员在编写代码之前先编写测试用例 ↩︎